Micro-Benchmarking Compiler Auto-Vectorization
One of my long time colleagues Brendan sent me a link that you can view HERE. Naturally, I opened it as soon as I got it... Several hours after he sent it. I was a bit confused when reading it, but he was of course busy doing other things. So I just spent some time looking at it.
I would like to say I was nerd sniped by him, but I doubt he really thought too much of it before sending it. Knowing Brendan better than I know assembly vector mnemonics, I spent more time thinking about why it was sent than what was sent. He is a long time proponent of some of the standards within RISCV, and as you can see below, it is comparing RISC-V, x86, and AArch64 across both GCC and Clang.
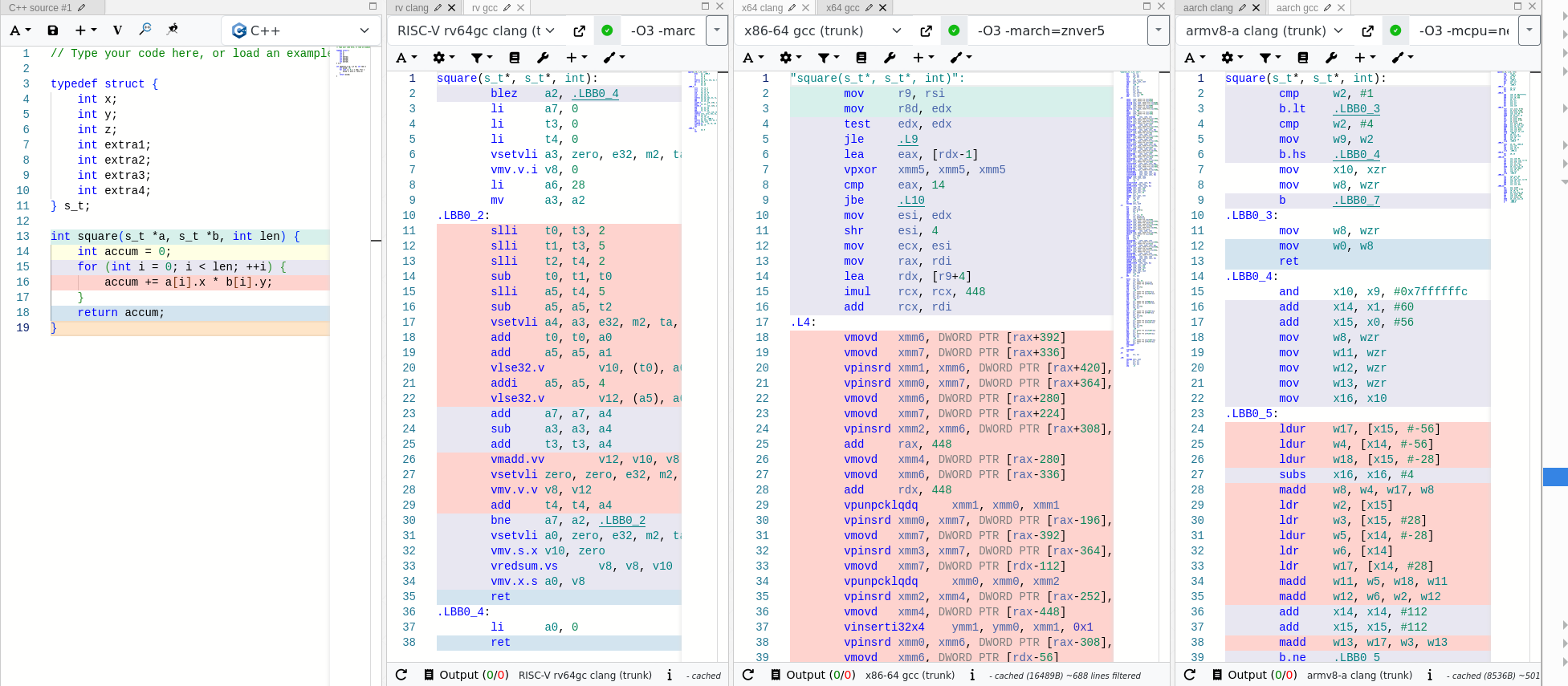
So I tried to spend some time thinking about why the RISCV approach might be better, the first thing that jumps out is that it is certainly shorter. This is even more true when only looking at the GCC results below.
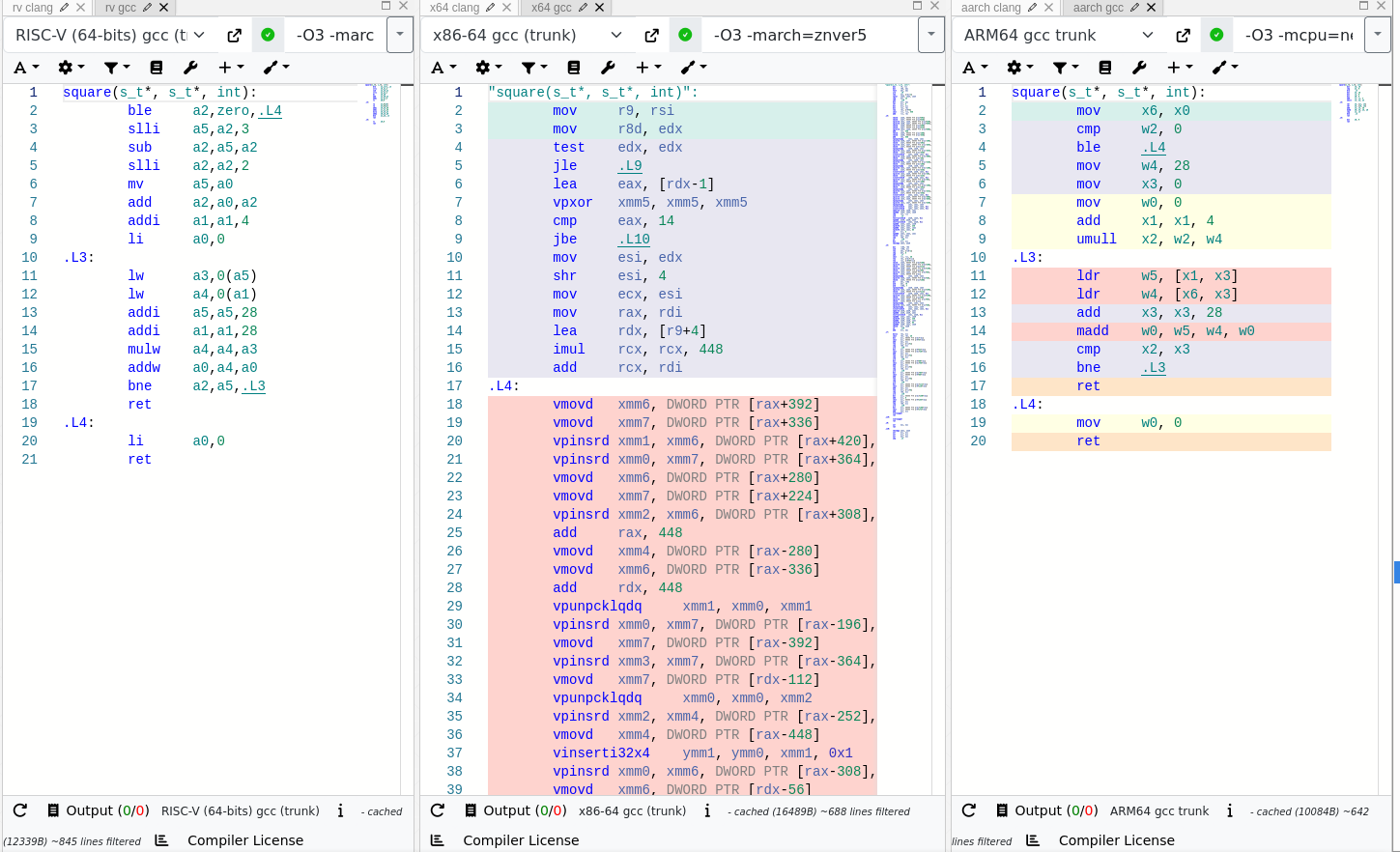
The best that I could understand the code without reading it, was that it is trying to hide xmm vector access latency by doing two in parallel. I did not realize this at the time, but Brendan had set the uarch to Zen 5. Without that information I guessed the compiler generally understood xmm to have latency worth hiding between operations. The next thing I saw was a long region of slightly similar code, with differing register offsets. My best guess was that this is due to alignment.
Consider the case where we want every third element but can grab 8 elements at a time. The first set, we want the 0th, 3rd, and 6th elements. The next time, we want the 1st, 4th, and 7th. After that, the 2nd and 5th. Finally, the pattern repeats. I suspected that the long code length was due to unrolling this pattern.
I had only recently learned that unlike x86, RISCV has gather/scatter vector instructions. Here, those instructions lead to a dramatically shorter unrolling since there is only one pattern instead of three: just grab every nth value until the register is filled.
Looking at ARM Clang/gcc I spent too much time trying to tell if the generated code was vectorized. But the best I could tell without looking was that it was only scalar code. My best guess was that this was a criticism of Arm's naming scheme, as the armv8-a compiler produced 'subjectively' worse code than the ARM64GCC compiler. My knowledge was that Armv8 is a big family, from the server Neoverse chips, to the ARMv8-M low power embeded MCUs. Again, I did not see that a specific CPU was specified here, so I assumed this is why auto-vectorization failed.
I had just pulled up the ARM wiki page, when Brendan finished talking. It turns out he was *just* welcoming me to a new plane of suffering featuring compiler idiosyncrasies and bugs, particularly with autovectorization. But nevertheless he humored my ideas, and we talked about the merits and functionality of the code.
He was doubtful the x86 code was properly generated, that while it was probably functionally correct, profiling had probably gone wrong in some way to create this abomination. I on the otherhand generally have faith in tools. I have only been bitten by issues that should have been obvious in the TI compiler, never something as battle tested as GCC. He remarked I could look around and see the sausage being made for myself, and that non-functional mistakes make it through the cracks.
This was the point where we started writing some test cases for the code. Test cases I spent hours of my day working on instead of taking a break from programing. A foolish choice in the end. I ended up making four test functions: one bare-bones case to measure loading and setup time, one expected to be trivially optimized out, and finally, the unaligned and aligned cases.
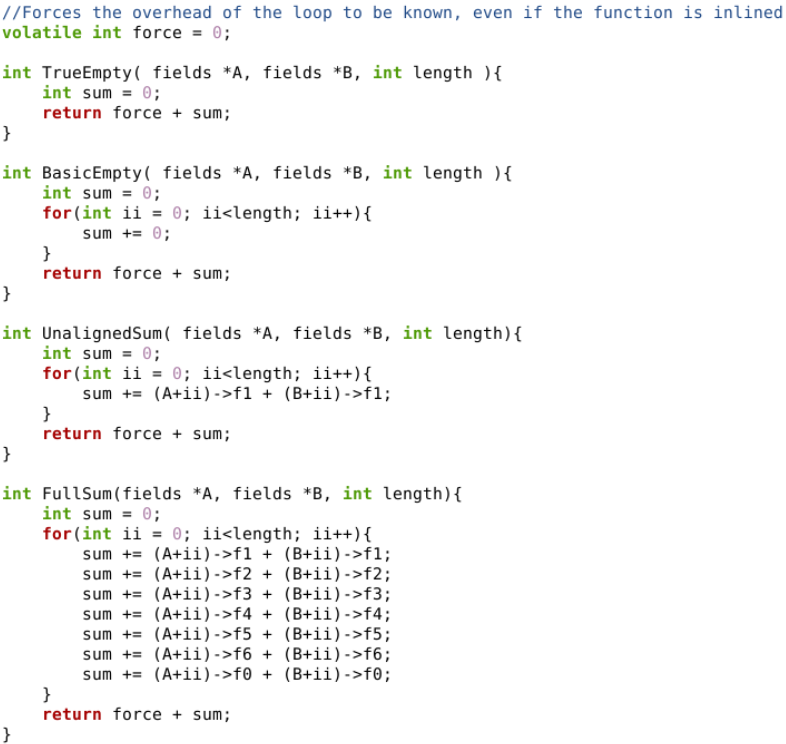
In the end, I 'won' an hour or two less sleep. But I would feel silly to do this if no one ever saw it. As expected when there is nothing to optimize, or the entire function is optimized out all tools perform similarly:


Once we look at the performance of the aligned and unaligned adds we see more realistic results:


In these more realistic cases it is no longer useful to keep the unoptimized data in the graph. Without it we first see the minor variations in the tools at optimizing a mostly empty script which is not too remarkable:


But this highlights a gap between GCC and Clang in vectorization:


This gap doesn't really go away, even when considering the different amounts of time the executables take to start up:


In fact the "Bad" vectorizatin of GCC does so much better it is worthwhile to remove clang from the results:

The raw data collected is available for viewing Here. The downloads have the assembly generated for these tests.
Recent Updates
Disaggregating Away The Stack's Coherence Tax With DCDS-ISA
The stack is mainly used for thread-private operations, yet modern microarchitectures are must treat stack accesses like interprocess communication just in case threads share data to mantain correctness. This means the Load/Store Unit wastes entries ch... Read More
Beyond Bit-by-Bit: The Math Behind Fast CRC32
While cyclic redundancy checks (CRC) are ubiquitous for data validation, their sequential nature seems like it should create a computational bottleneck. This post explores the polynomial math required to parallelize CRC32, and the hardware-software co-... Read More
A Microarchitecture Retrospective
Microarchitecture is Yale Patt's signature class and widely considered the hardest course offered by the department. But is it the best place to learn CPU design, when the assignment makes you balance design complexity and tooling development against a... Read More
Just like cats
Sometimes I look at my sisters cat and wonder what he can understand. My sister's cat is named Boba. He is a good sort of fellow, well behaved, polite... endlessly hungry. Often, I look at him and wonder what he sees. Of course his vision is different ... Read More
More Than a Robot Couch
Fundamentally, engineering is just about choosing whats best. The hard part is just figuring out what is best. Getting caught up in my regrets used to feel like progress. After all, introspection is the first step to improvement. While important, intro... Read More
My Custom 8-Bit CPU
How I learned to let go of small things like ‘value proposition’, ‘opportunity cost’ and ‘reason’ in order to embrace the transistor. In the later half of my internship at AMD in 2019, I was struck by the Muse. I had just seen the Monster 6502, which i... Read More
On The Balance Of Words
Being clear about what you mean is a skill, but being clear while avoiding accountability for the consequences is a profession Everybody knows that lying is wrong. Or at the very least, that lying too much will get you in trouble. Everybody also knows ... Read More
