Beyond Bit-by-Bit: The Math Behind Fast CRC32
Cyclic redundancy checks (CRC) are standard mechanisms used to validate file and message integrity across computing environments. However, the fundamental operation of a CRC—computing the remainder of a polynomial division—is inherently sequential. Naively resolving a CRC bit-by-bit introduces latency that scales linearly with the message size. How modern hardware and software implementations sidestep this bottleneck to achieve high-throughput processing is the core focus of this post.
When researching, I realized that much of the existing literature heavily indexes on specific implementations or leans strictly toward pure math. This post is meant to bridge that gap. My goal here (beyond acting as notes for my future self) is to motivate how these techniques work at the algorithm level rather than the implementation level.
For those looking to supplement this mathematical breakdown with specific code, the following foundational resources are highly recommended. Komrad36’s guide is an excellent resource for x86, and I found WoWaster's post on RISC-V Vector CRCs to have the most helpful diagrams:
- Komrad36's Guide to CRC
- Intel's Whitepaper on the CRC instruction
- FPROX's Accelerating CRC with RISCV Vector
- WoWaster's RISCV Vector CRC implementation
- Barrett reduction for polynomials from CORSIX.ORG
The first thing to consider is what 'is' a CRC32, as after all CRC is a generic term. A concise (but jargon heavy) definition is that CRC32 is a non-cryptographic hash which finds the 32 bit remainder of the input data when divided by a polynomial (IEEE or Castagnoli) in GF(2). To complicate things a little more, real implementations like from Boost have complications beyond the division itself, namely initial/final XOR values, and reflecting the input/output.
Let's start unpacking some of the jargon. GF(2) is a 'finite field with two elements', or oversimplified a number system with only 0 and 1. The first question you might have, is that if the number system only counts to 1, what happens when you do 1+1? The simple answer is we wrap around to zero. A table is shown below which shows the definition for multiplication, addition, and subtraction. A key thing to note, is that add/subtract looks like an XOR, while mul/div have a similar definition to normal but are constrained by the limited number of states in GF(2).
An easy thing to gloss over, is that GF(2) is not binary. In binary we can have a representation for 6, it is simply 0b0110, while 6 is definitionally unrepresentable in GF(2). The limited size of GF(2) makes all operations simple binary operations, but GF(2) only defines two numbers representable in a single binary bit.
| Add (XOR) | Sub (XOR) | Mul (AND) | Div |
|---|---|---|---|
| 0 + 0 = 0 | 0 - 0 = 0 | 0 * 0 = 0 | 0 / 0 = Undefined |
| 0 + 1 = 1 | 0 - 1 = 1 | 0 * 1 = 0 | 0 / 1 = 0 |
| 1 + 0 = 1 | 1 - 0 = 1 | 1 * 0 = 0 | 1 / 0 = Undefined |
| 1 + 1 = 0 | 1 - 1 = 0 | 1 * 1 = 1 | 1 / 1 = 1 |
This limitation may seem fatal, after all the data that we are performing the CRC on is likely longer than one bit in length. This is where the polynomial aspect of the definition comes back in. If we construct an ordinary polynomial, where each coefficient is an integer in GF(2), we can now define operations on data longer than one bit. A canonical implementation is to have each bit in an integer represent the coefficient of of the polynomial. Although 0b0110 is 6 in binary, we could also read it in as the GF(2) polynomial x^2 + x.
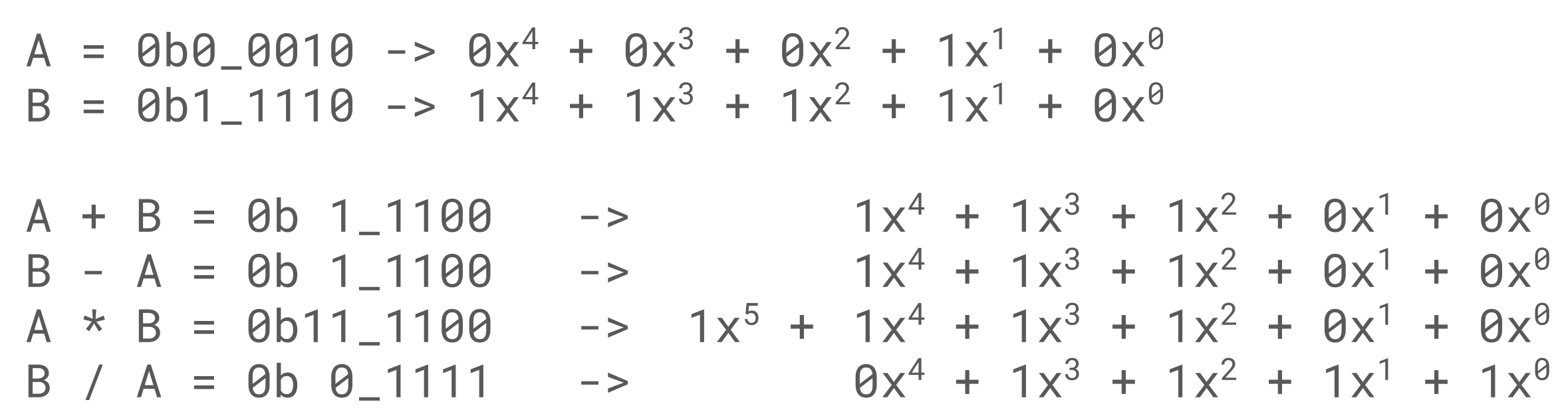
This polynomial representation ties into how this is a hash function. Hash functions simply take in data of any length to produce a fixed length output. Hash functions can be very simple; f(x) = 42 is a hash function for instance. No matter the input the output is fixed size. Some attributes that make a hash function good are irreversibility, resistance to collisions, and its avalanche characteristics. A non-cryptographic hash will typically compromise on one of the factors that make a good hash in the name of speed. Here a polynomial division is a hash function, as the coefficients are bounded in size to one bit, and the degree of the remainder will always be less than the divisor.
An example of polynomial division is shown below. An interesting thing to note, is that although we are subtracting from the original value, the net result is either the term exists or doesn't and so 0 - 1 = 1 in GF(2). Mechanically, it is also useful to note how subtracting in each row always results in the most significant term of the remainder being removed, and set bits in the polynomial divisor result in the coefficients being flipped. This propagation of flipping bits causes a single bit error at the beginning of the message to propagate (Avalanche) through the whole message. A weakness (That we will find to be useful) is that any number of zeros at the start of a message will result in a collision, and the algorithm is simple and fast enough to make arbitrary hash generation possible.
One issue with just taking a remainder is that changes in the 32 least significant bit are only XORed into the output instead of being given a chance to avalanche. The simple solution that CRC32 takes is to add 32 bits of padding to the right of the data, so that every bit gets an equal chance to cause chaos. An exercise left to the reader is to consider the difference in remainder when dividing 0b0001000101, 0b1000100, 0b1100101, and 0b1100101000 by 0b1011 in contrast to the division shown below of 0b1000101 by 0b1011.
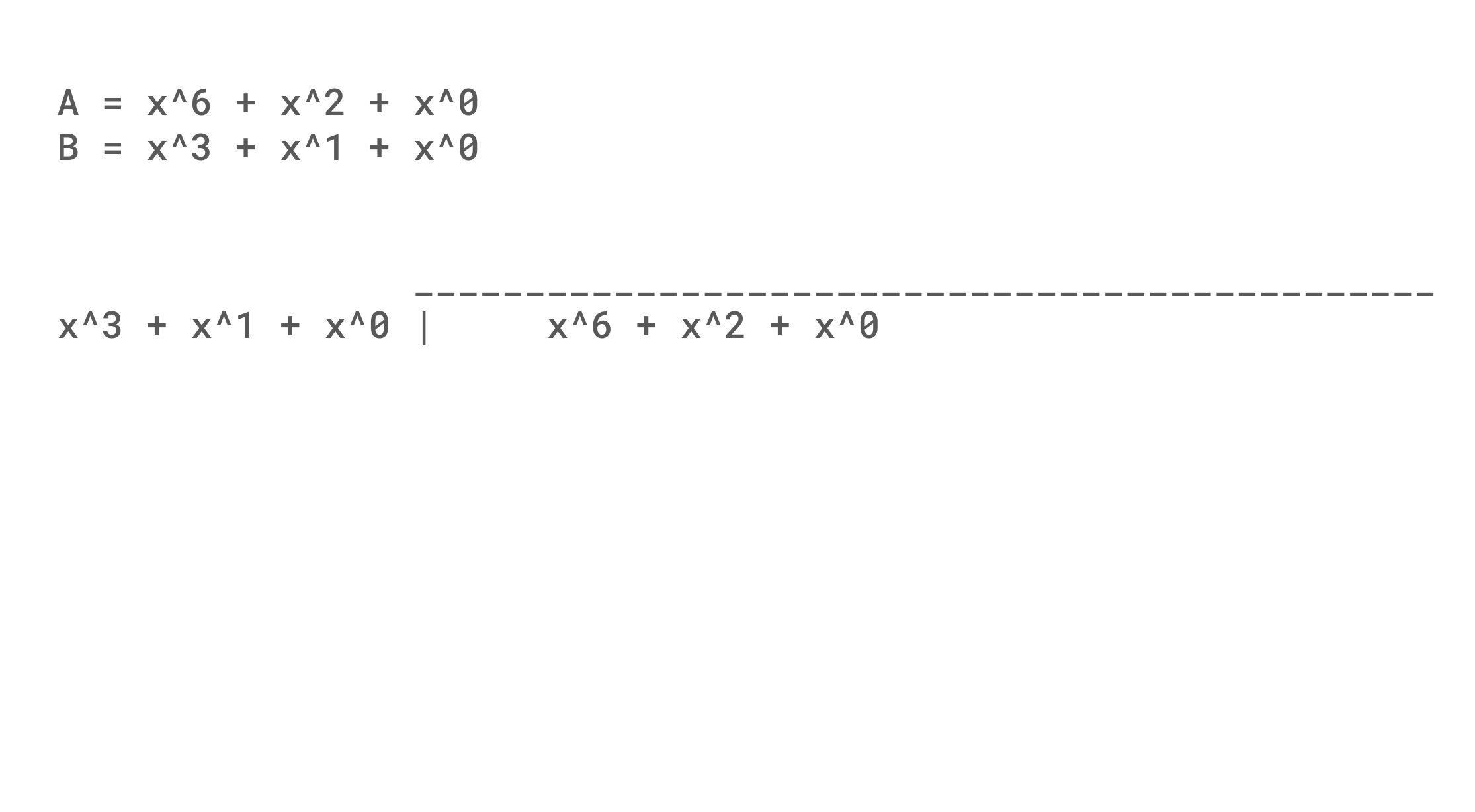
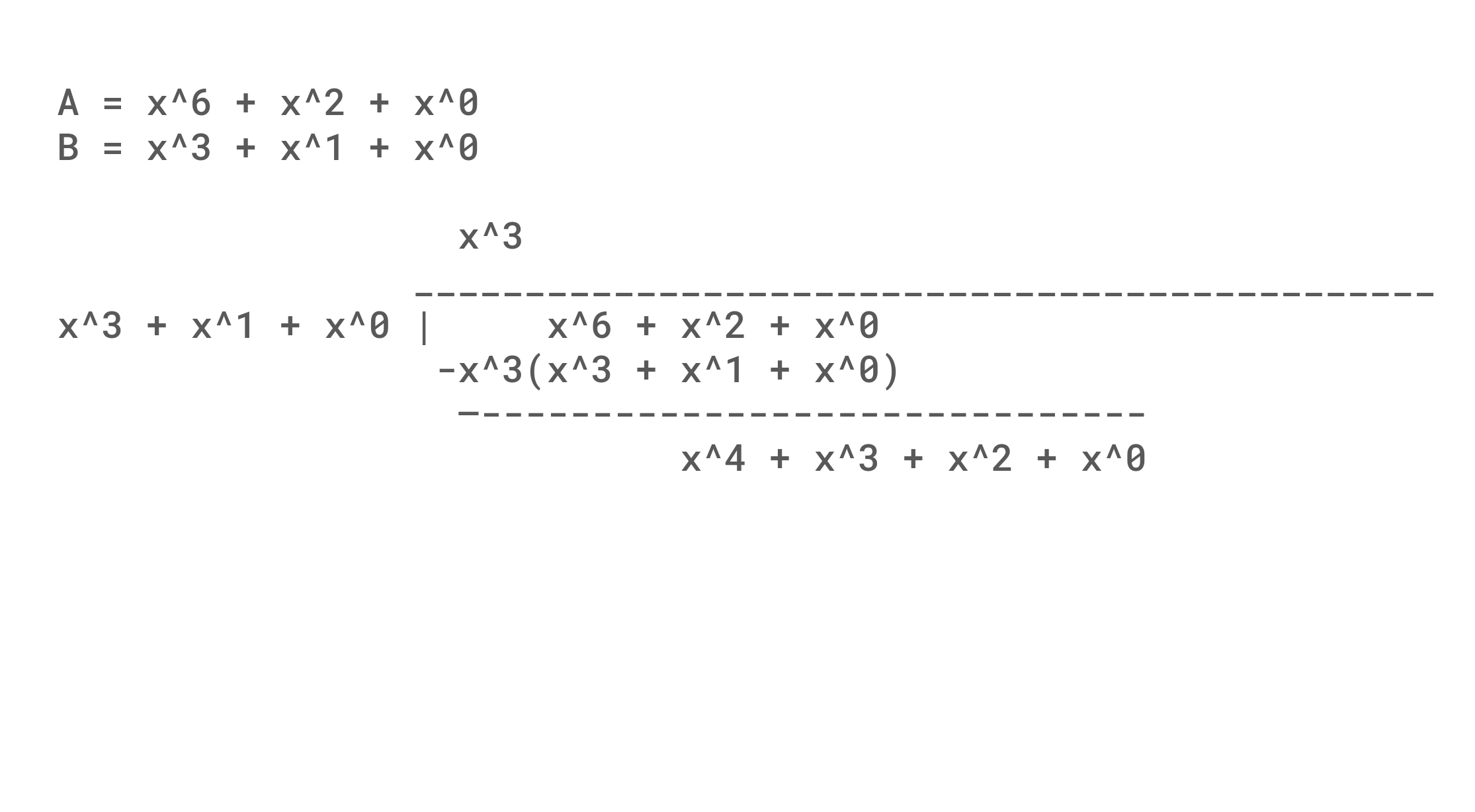
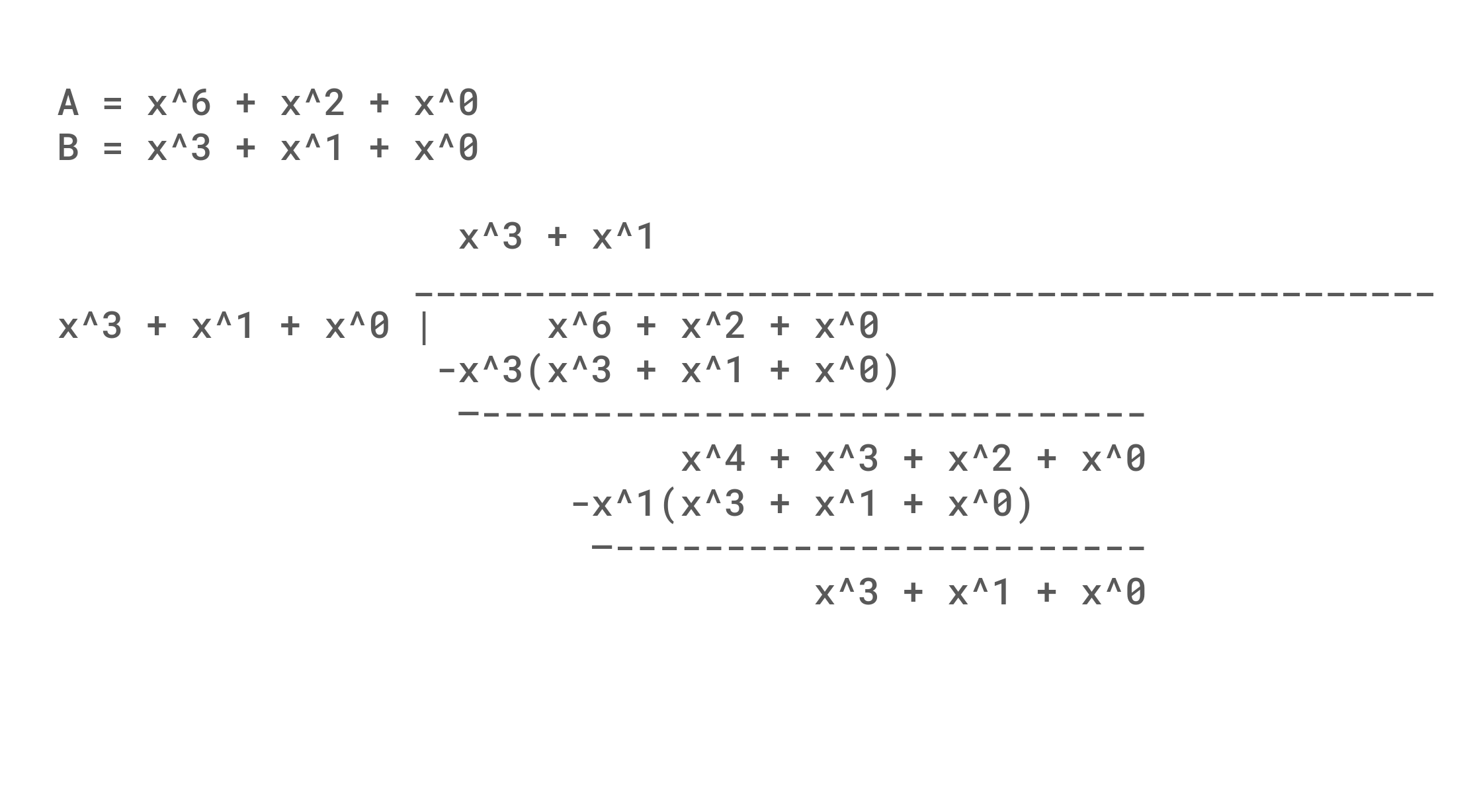
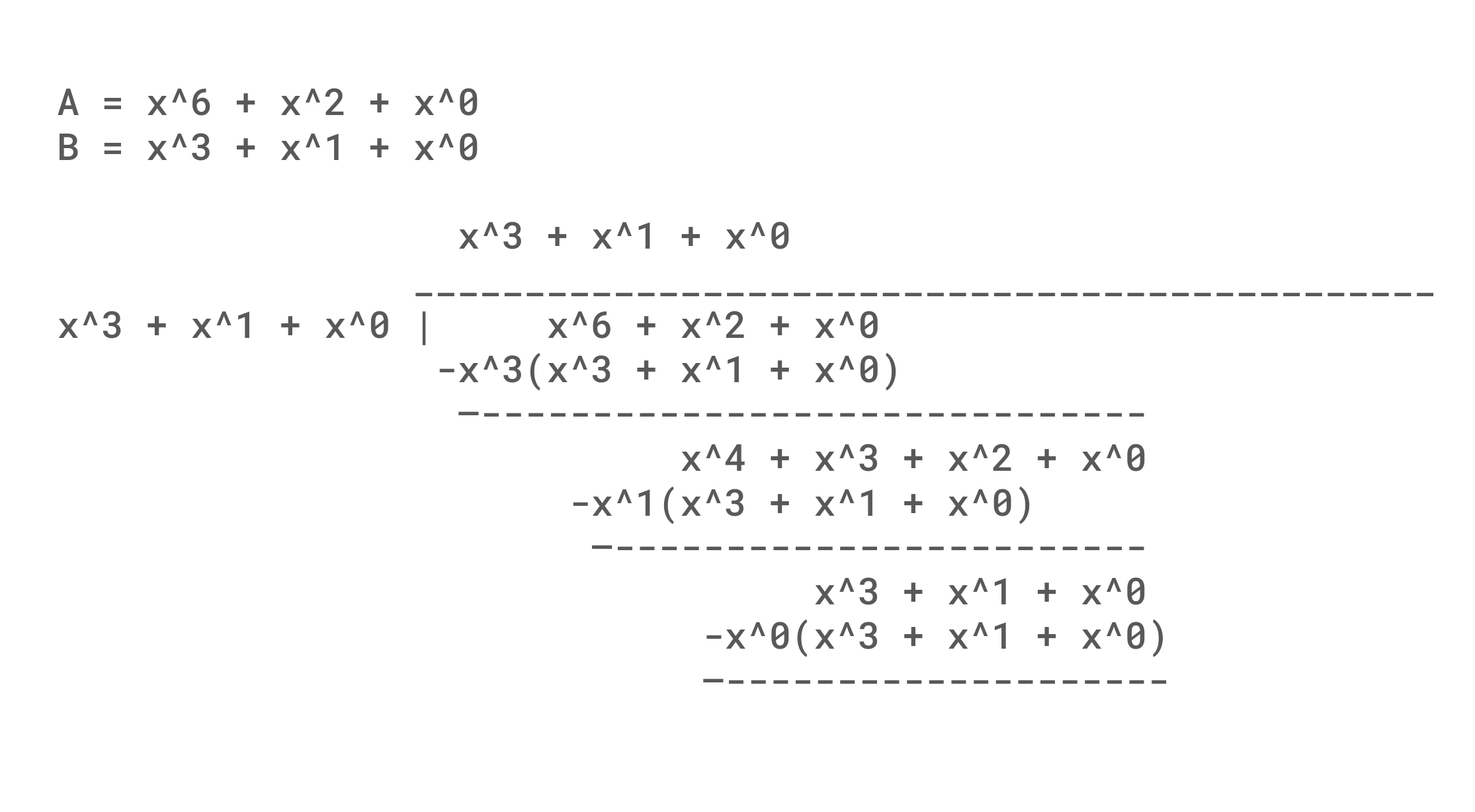
Considering the remainder is 32 bits, this implies that we need a polynomial of degree 32 (33 bits). Since x^32 definitionally will have a coefficient of 1 for a polynomial of degree 32, it is often not written. Although in principle any polynomial could be chosen, there is standardization for both clarity and quality reasons. CRC32's classic flavor used for Ethernet is defined in IEEE 802.3, while the Castagnoli polynomial for CRC32C was found later to have a larger hamming distance and handle larger burst errors than the original. These two polynomials are commonly stored in their reversed representations in part due to the endianness of data formats and machines that calculate them.
| CRC Flavor | Nominal | Reversed |
|---|---|---|
| CRC32 | 0x04C11DB7 | 0xEDB88320 |
| CRC32C | 0x1EDC6F41 | 0x82F63B78 |
Lets now consider a more concrete implementation which is shown below. Lets assume for simplicity that the data in the array is such that the highest degree polynomial is the MSB of the data in index 0 of the array and the degree represented by each bit decreases as you go towards less significant bits and towards higher indexes.
uint32_t crc32( uint8_t data[], size_t data_length){
uint32_t hash = 0x0000'0000;
for(size_t ii=0; ii<data_length; ii++){
hash ^= (((uint32_t)data[ii]) << 24);
for(size_t bit_idx=0; bit_idx<8; bit_idx++){
hash = hash & 0x8000'0000 ? (hash<<1) ^ CRC_POLY : (hash<<1);
}
}
return hash;
}
The reason I pointed out the order of data, is that the required order to calculate a CRC may not be intuitive. Many devices calculate CRCs because CRCs have easy and fast logic to implement. These devices might not have the same byte ordering, or due to backwards compatibility, the notional order to ingest the bits in the right order may differ. One historical reason is endianness and available instructions. To compute the same CRC on different machines can require changing the traversal order of the data, and/or reflecting the input/output of the CRC. This explains some of the settings boost offers: the XOR at the start improves sensitivity to message length, while the XOR at the end is a convenience feature useful for implementations (See Appendix 2 for more detail).
| Address | Big Endian | Little Endian |
|---|---|---|
| 0x1000 | 0x00 | 0x03 |
| 0x1001 | 0x01 | 0x02 |
| 0x1002 | 0x02 | 0x01 |
| 0x1003 | 0x03 | 0x00 |
One thing that might seem odd is that although our hash is 32 bits we are only bringing in 8 bits at a time. This is a minor optimization that allows us to skip padding the end of the message with zeros. The reason this works is because only the most significant bit needs to be fully calculated to determine what bit flips will occur. The hash here conceptually is only the 32 polynomial terms with the highest degree. Because GF(2) has such a simple definition, if a polynomial is nonzero, we just need to subtract a notionally shifted polynomial if the highest degree is set.
More formally we can write CRC32( D(X) ) = D(X) * x^32 mod P where the data is written as a function of X reflecting CRC's interpretation of X as a polynomial. If we consider D(X) to be made of two parts where DH(X) + DL(X) = D(X) (e.g. [x] + [1] = [x + 1]) then it should follow that CRC32(D(X)) = CRC32(DH(X)) ^ CRC32(DL(X)) because we can take each side mod P effectively turning the equation into CRC32(D(X)) = DH(X) * x^32 mod P ^ DL(X) * x^32 mod P.
This version of the equation would allow us to handle each byte individually, then xor the results of each CRC to get a final CRC. Note that this equation is too limited as we do not calculate the hash of each byte for the full length, instead we are finding the impact of the hash from 8 bits on the neighboring 32 bits.
The work for this result is shown below, note that in GF(2) multiply still is distributive over addition, and N is any integer greater than 0.
- CRC32( D(X) ) = D(X) * x^32 mod P
- CRC32( D(X) ) = (DH(X) + DL(X)) * x^32 mod P
- CRC32( D(X) ) = (DH(X) * x^32 + DL(X) * x^32) mod P
- CRC32( D(X) ) = (DH(X) * x^32 + DL(X) * x^32) * (x^N/x^N) mod P
- CRC32( D(X) ) = (DH(X) * x^32 / x^N + DL(X) * x^32 / x^N) * (x^N) mod P
- CRC32( D(X) ) = (CRC32(DH(X) / x^N) + DL(X) * x^32 / x^N) * (x^N) mod P
- CRC32( D(X) ) = (CRC32(DH(X) / x^N) * (x^N) + DL(X) * x^32) mod P
- CRC32( D(X) ) = CRC32( CRC32(DH(X) / x^N) * (x^N) ^ DL(X))
This equation justifies why we were able to pull in a byte of data at a time in the prior code where N=8. The term CRC32(DH(X) / x^N) * (x^N) in that code simply means we compute the CRC32 of DH(X) as if it was truncated, then we can finish the CRC by XORing that result in with DL(X) to continue the calculation as if we did not split DH(X) and DL(X).
This more formal definition opens the door to our first optimization of table based lookups. We might want this optimization as one property of the initial code is that we are only resolving one bit for every iteration of the for loop. If you want to think about how for a second, look at the previous code, and consider how many options there are for DH(X). Although we need the current hash value, and the next data, we fundamentally only have 8 bits of state. These 256 options are very cheap to compute ahead of time, and convert several rounds of bit manipulation into a couple of cycles to perform a table lookup as shown below.
uint32_t crc32( uint8_t data[], size_t data_length){
uint32_t hash = 0x0000'0000;
for(size_t ii=0; ii<data_length; ii++){
uint32_t lookup_value = lookup_table[(hash>>24) ^ data[ii]];
hash = (hash<<8) ^ lookup_value;
}
return hash;
}
The table based method looks doomed to scale poorly. We need exponentially more storage to only increase the number of bits we are resolving linearly. Worse than that, while 256 four-byte entries is small enough to fit in the fastest layer of cache, larger tables only fit in slower and slower memories. Eventually, a large enough table may be significantly slower than the naive solution if the table does not fit in the cache at all.
To unlock more speed we need another trick. A natural starting point is to try applying the table math we found repeatedly. We might try to create some D'(X) which is equal to the remaining DL(X) creating a new opportunity to do a lookup for the newly defined DH'(X). Unfortunately, this implementation does not have the complete DH'(X) to do the lookup with until DH(X) is found (as DH(X) will flip bits in DL(X) and thus our new D'(X) will change). This means we see no speedup by applying the exact same trick twice, but there is still opportunity.
If you would like to take a shot at this problem, two guiding questions are what happens when the leading bits of a hash are all zeros, and what can we do if we pretend that DL(X) is longer than it really is. Equivalently, what if we assume there is an 'easy' to compute gap of zeros in the message of length g where DH(x) ^ DL(X) = D(X) but the lowest degree of DH(X) is at least g larger than the highest degree of DL(X). This line of thinking is followed to conclusion in Appendix 1.
The cleanest reasoning follows by simply extending DH(x) ^ DL(X) = D(X) for a fixed size data block and trying to apply small lookup tables. Let D(X) be a 64 bit block of data we are performing a CRC on, where we have DA(X) to DH(X) where the XOR of all 8 elements equals D(X). It is then also true that the XOR of the CRCs of DA(X) to DH(X) is the CRC of D(X). Because DA(X) has 56 bits of zeros (Any ones from D(X) in these lower positions are in segments B to H, not A) there are only 256 possible values of DA(X) so we can precompute and save the result. We can create a table for each segment.
This lets us use 8KB of data for tables to gain more parallelism in computing 64 bits of CRC. Combining this with our prior work we can enlarge the size of data we are breaking off DL(X) from the prior section to 64 bits, computing the upper bits of DH(X) as if it was a shorter CRC, and relying on DL(X) to propagate this partial CRC to the end. A visualization of this is shown below.
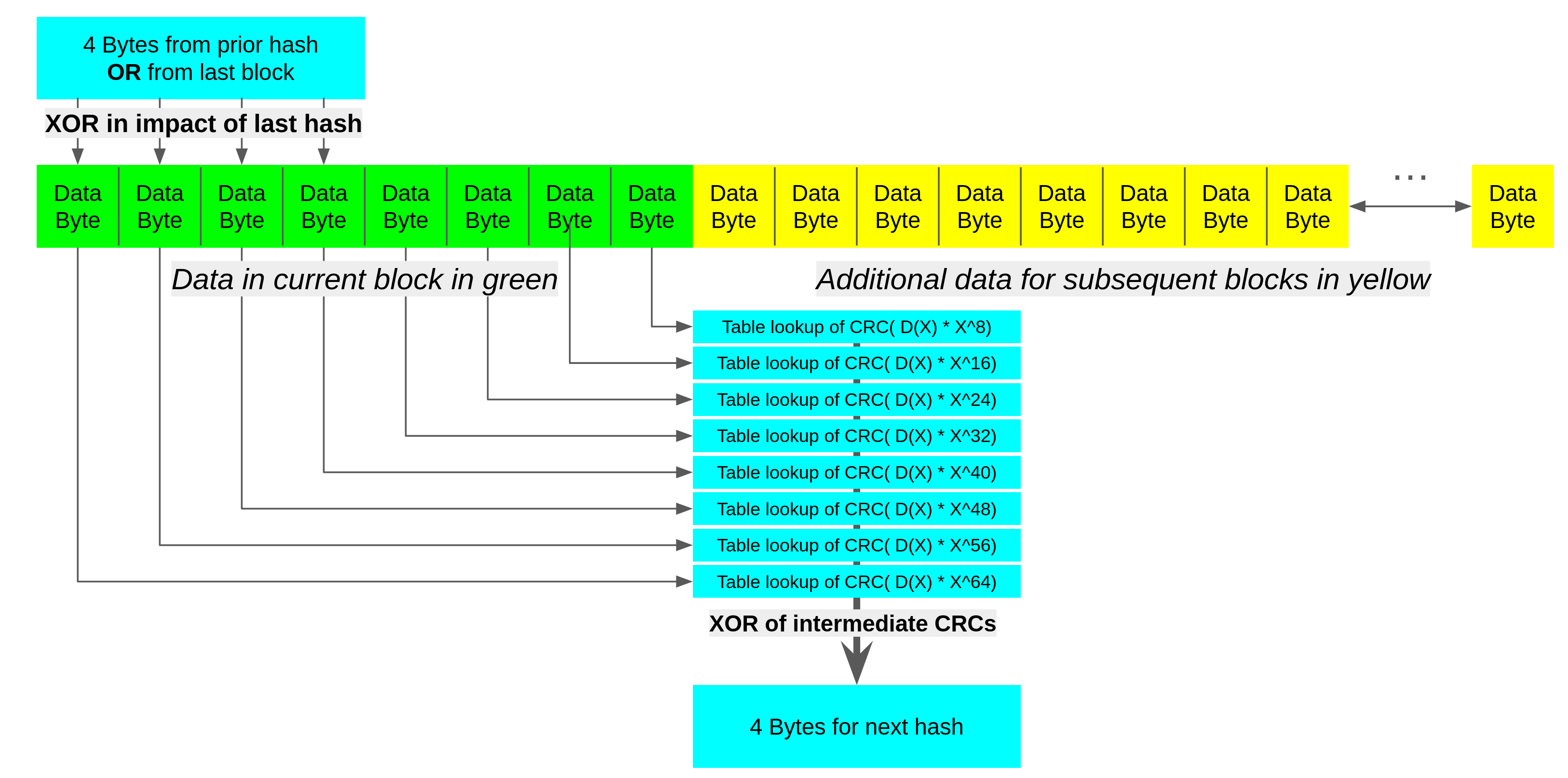
One thing you might notice in the table based approach is that there are still some dependencies we must resolve in order to perform lookups. Namely, because we need to take a starting hash value, and because we must reuse the same lookup tables, the first 32 bytes of a block waits for the prior block to finish completely.
So far we have been relying on computation and tables to achieve speedup. This makes sense as we can only do adds and shifts cheaply, and even then the latency can hurt. Another approach is to try to target aspects of the algorithm more directly. It is important to remember that in GF(2) a multiply is just AND, and extending this to the polynomial case is relatively cheap. Even more so as CLMUL and MUL share a lot of the same structure as shown below.
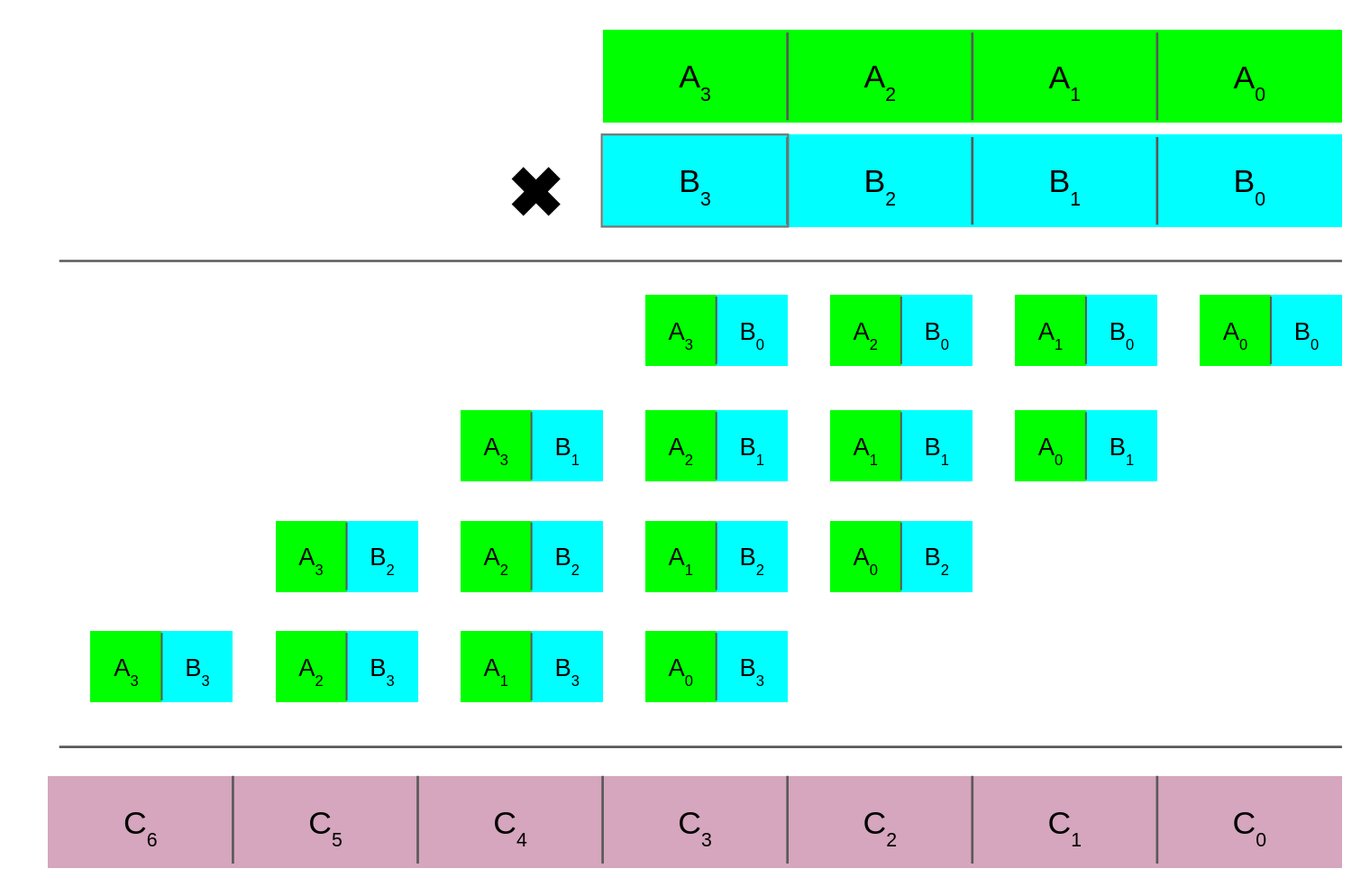
In normal multiplication C_2 for instance is the sum of its column plus the carry of the column for C_1. In a carry-less multiply C_2 is the XOR reduction of the column (a half adder is like an XOR, except it also propagates a carry which is not needed here). The addition of the ability to do a carry-less multiply opens the door to more tricks. The first of which follows from CRC32(D(X)) = CRC32(DH(X)) ^ CRC32(DL(X)) where we create DH(X) that has a long sequence of zeros.
- CRC32( D(X) ) = CRC(DH(X)) ^ CRC(DL(X))
- Let N be the degree of DL(X) and dh(x) be the most significant bits of DH(X)
- CRC32( D(X) ) = CRC(dh(X) * x^N) ^ CRC(DL(X))
- CRC32( DH(X) ) = CRC(dh(X) * x^N)
- CRC32( DH(X) ) = (dh(X) * x^N) * x^32 mod P
- CRC32( DH(X) ) = (dh(X) * x^32) * x^N mod P
- CRC32( DH(X) ) = (dh(X) * x^32 mod P) * (x^N mod P) mod P
- CRC32( DH(X) ) = CRC32(CRC32(dh(X)) * (x^(N-32) mod P))
- Alternatively: CRC32( DH(X) ) = CRC32(dh(X)) * CRC32(x^(N-32)) mod P
The consequence of CRC32( DH(X) ) = CRC32(CRC32(dh(X)) * (x^(N-32) mod P)) is that similar to the precompute table of fixed offsets we can now do variable offsets in one step. If we have some way of computing a CRC in a serial way, we can turn it into a parallel way. This is the essence of what I call braiding.
If you have a fast way of computing a fixed size CRC, you can precompute x^(N-32) for differing N such that you combine the results from these parallel blocks. Conceptually this is similar to the table based work we did earlier. The key difference is that before we were looking at 32 bit results from a table lookup based on the most significant 8 bits of the data XORed with previously calculated remainders (when applicable), and we needed a table for each offset.
Because each table takes space in the cache, it can be slow to have a table specifically for calculating this braiding effect. With clmul, we precompute a single 32 bit constant, multiply it with our partially computed CRC to apply this 63 bit remainder somewhere later in the stream.
The impact of this is shown below where this lets us increase the parallelism of the CRC, which can be helpful if we have pipelined hardware or multiple functional units which need distinct streams to achieve higher throughput.
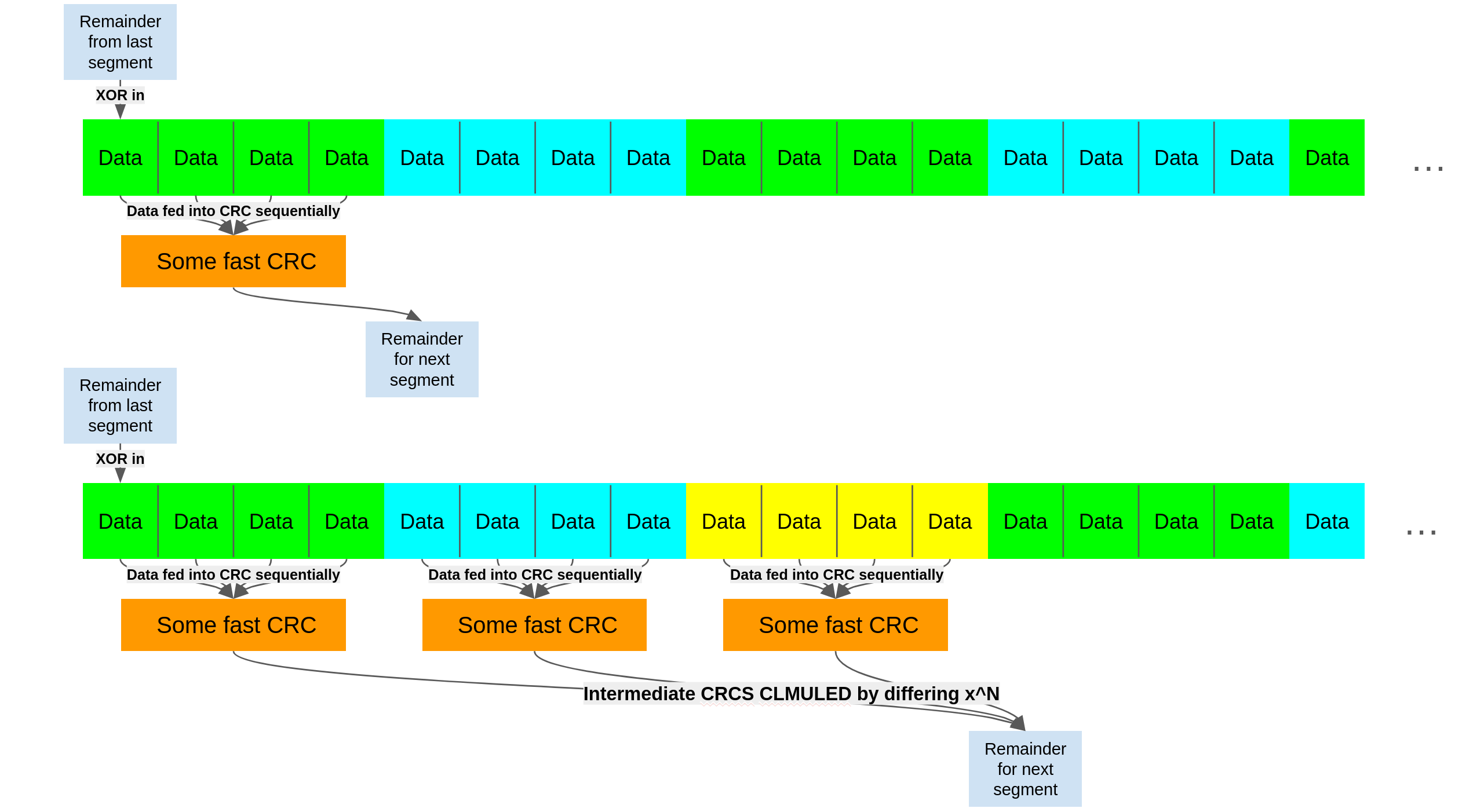
The natural extension of braiding is to simply remove the 'performing a fast CRC' part of the equation. Earlier when we wrote CRC32( DH(X) ) = (dh(X) * x^32 mod P) * (x^N mod P) mod P we made a choice to cast (dh(X) * x^32 mod P) into a CRC. We can in fact just find the impact of dh on bits some number of bits to the right. A naive implementation might look like before, moving the impact of a block to one location, reducing the intermediates, then XORing into the next block to repeat as shown below.
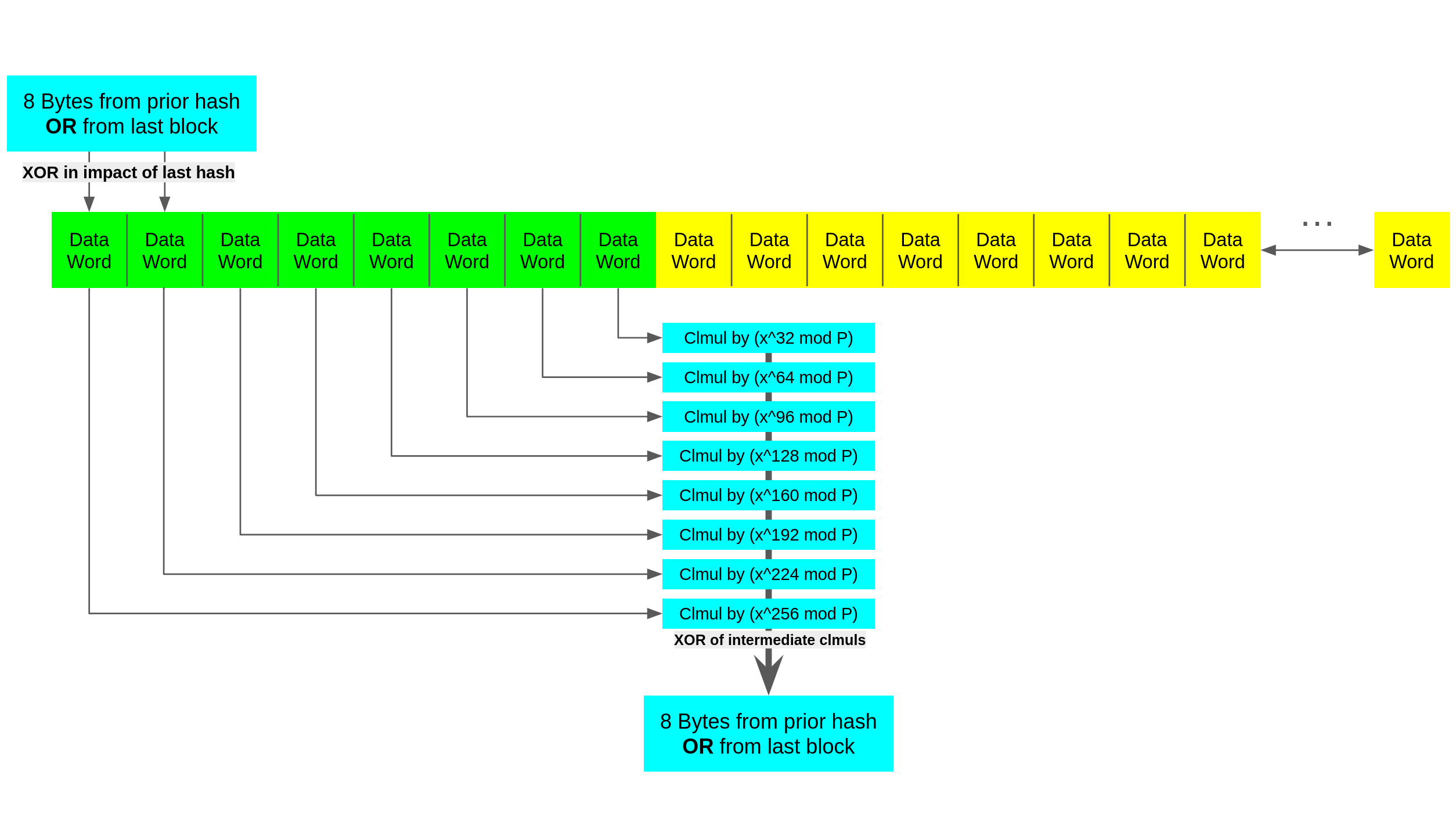
The reason this approach is naive is we create a single point of dependency between the parallel executions like before. We also require many constants increasing register pressure. We can use fewer registers to hold constants, and have data show up in similar locations by folding more evenly, as shown below.
At first the choice to use two folding constants instead of one might seem odd. Because the largest result mod P is 32 bits, and we are CLMUL'ing two segments together the results will be 63 bits in length. If we did this truly evenly with one constant like x^256 we would need to XOR elements at a 32 bit granularity instead of a 64 bit one implying more shuffling/selection to XOR the right data together.
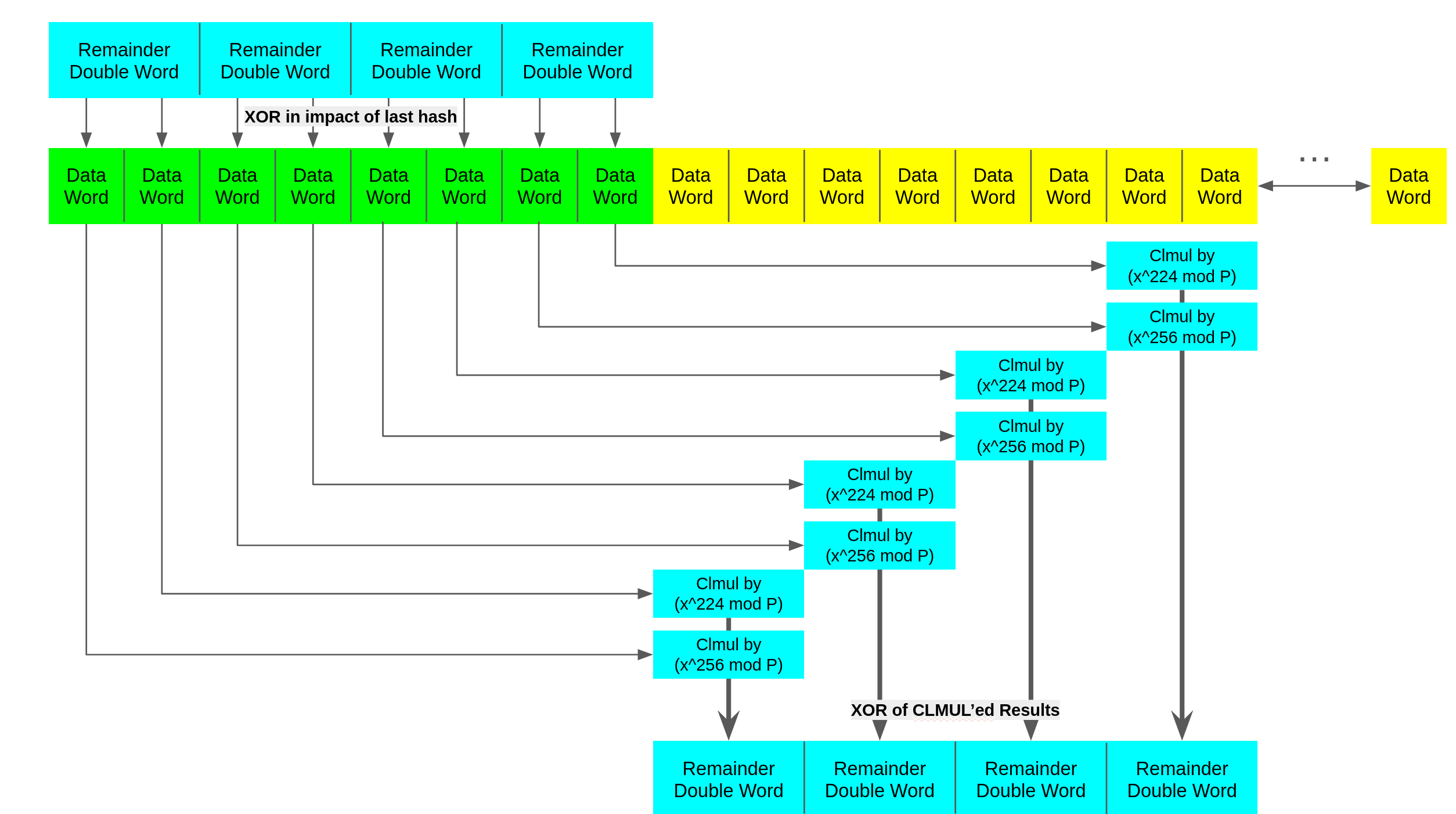
An important thing to notice about folding is that we are not directly calculating a CRC, it is more akin to finding a shorter polynomial that when CRC32 is done to it, will have the same result. Therefore the last pass needs to be done with a different method than folding.
The table based methods we addressed earlier had the attribute that they amortized the initial expensive cache misses when loading from the table over many iterations. So it is not a good optimization to use a table for a short message. We could perform the final reduction naively, but one method that CLMUL allows us to implement is Barret reduction.
Essentially we precompute a reciprocal then shift out the rounded bits. The reason that this works is that depending on the number system some division will happen to be cheap. An analogy to the polynomial GF(2) barret reduction below is that we can divide by 17 by multiplying by 58 then dividing by 1000. If our hardware has a fast multiplier and at least some division can be fast (Like division by powers of two) we can precompute a constant to do the reduction. More formally, for a short message M, and large constant T:
- T can be chosen such that:
- Division is just a shift (Any polynomial with only one bit set)
- T is larger than the post fold remainder so the approximation is exact
- T/P multiplied by the remainder fits conveniently within a hardware register
- floor(T/P) can be precomputed as constant K
- CRC32(M) = M(X) mod P
- CRC32(M) = M(X) - (M(X) * K)/T mod P
- CRC32(M) = M(X) ^ CLMUL(P, CLMUL(M(X), K) >> 96)
Combining these techniques allow users (mainly library writers) to create performant CRC kernels by creating parallelism in what seems like a strictly serial process. The main limitation for CRC32 throughput when the hardware has sufficient functional units is often the bandwidth available to the core to bring in data that needs to be hashed. This bandwidth limitation is another reason that table lookups are not preferred over other computation methods like CLMUL.
Appendix 1.
- CRC32( D(X) ) = D(X) * x^32 mod P
- CRC32( D(X) ) = (DH(X) + DL(X)) * x^32 mod P
- CRC32( D(X) ) = (DH(X) * x^32 + DL(X) * x^32) mod P
- CRC32( D(X) ) = (DH(X) * x^32 + DL(X) * x^32) * (x^N/x^N) * (x^g/x^g) mod P
- CRC32( D(X) ) = (DH(X) * x^32 * (x^g /x^N) + DL(X) * x^32 * (x^g /x^N) * (x^N/x^g)) mod P
- CRC32( D(X) ) = (CRC32(DH(X) / x^(N-g)) + DL(X) * x^32 * (x^g /x^N) * (x^N/x^g)) mod P
- CRC32( D(X) ) = (CRC32(DH(X) / x^(N-g)) * x^(N-g) + DL(X) * x^32) mod P
The addition of g is in some sense overly trivial. We had no constraints on N why not just use a different size N, similarly why say that g is only a region with zeros in the source data? The answer comes in the usage, the insight is that this formula is letting us 'move' the 32 bits impacted from DH(X) to a spot of our choosing g bits to the right. By limiting the region we are moving this impact over to only zeros we can then recompute a table of 256 entries for an 8 bit block of data.
Similar to how CRC32(D(X)) = CRC32(DH(X)) ^ CRC32(DL(X)) lets us look at the high and low sections of D(X) separately, we can look at sections of DH(X) separately. If you consider DH(X) in 8 bit segments where all the segments XORed together is DH(X). Because each segment only has 256 possible states despite being longer than 8 bits, we can have a small set of lookup tables.
Appendix 2.
One property of the polynomial GF(2) remainder underlying CRC32 which is good and bad is that prepending zeros does not change the value of the remainder. The reason generalizes from the process of taking a normal remainder. Consider taking the remainder of 5, 05, and 005 when dividing by 2. They all result in the same value, because there is nothing for the division to do in these leading zeros.
The fact that the leading zeros do not impact the remainder is incredibly convenient for us as it enables transformations we use in order to get speedup. Because CRC(0) = 0 is the identity for one input, XORing any segment with zeros does not change its remainder. This property that there is a value that maps to itself is what lets us treat segments of the CRC32 independently. The fact that this occurs at zero is particularly convenient as it means we do not have to XOR D(X) to split it up, we can simply examine a segment independently. The linearity and the dead-zone in the mapping of CRC are in some sense weaknesses. They contribute to CRC32's cryptographic insecurity. But these properties also give us openings to speed up its computation.
The solution to both weaknesses is to simply move them to places where they are less likely to impact the final result negatively. Long blocks of zeros are common in hardware, and may erroneously show up in messages. If we are unlucky a long section of the start of the message may be zero, and we will be insensitive to this error. One way to cheaply mitigate (but not fix) this problem is to XOR some value into the first byte of the data. Since we don't want to actually modify the user's data, we accomplish this by initializing the hash value to some nonzero value such as 0x42.
To some degree setting the initial value of the hash to 0x42 only shifts the problem. If we happen to have the value 0x42 as the first byte, and we XOR in 0x42 from the hash, we will still not be sensitive to the length of a potential following block of zeros. The benefit is what the hash is vulnerable to is less common than the original vulnerability. it is for this reason that many CRC32 implementations set the initial hash value to 0xFFFF'FFFF.
Because we XOR values at the start of the CRC32, sometimes it is convenient to do the same thing at the end of a CRC. This aids in chaining functions for library writers as you might know the function you are calling will have an initial hash value you don't want to use. It is also common to need to XOR the output to match an existing standard. It is often a desirable result that the CRC32 return a nonzero hash, and hashing zeros is surprisingly common (hardware padding, empty buffers, etc.). Because of this some standards have similarly moved this problem elsewhere by having a final XOR to perform at the end. If we want our hashes to match theirs, we will have to do the same behavior.
P.S. You can access the Slides for the diagrams hereRecent Updates
Disaggregating Away The Stack's Coherence Tax With DCDS-ISA
The stack is mainly used for thread-private operations, yet modern microarchitectures are must treat stack accesses like interprocess communication just in case threads share data to mantain correctness. This means the Load/Store Unit wastes entries ch... Read More
Beyond Bit-by-Bit: The Math Behind Fast CRC32
While cyclic redundancy checks (CRC) are ubiquitous for data validation, their sequential nature seems like it should create a computational bottleneck. This post explores the polynomial math required to parallelize CRC32, and the hardware-software co-... Read More
A Microarchitecture Retrospective
Microarchitecture is Yale Patt's signature class and widely considered the hardest course offered by the department. But is it the best place to learn CPU design, when the assignment makes you balance design complexity and tooling development against a... Read More
Just like cats
Sometimes I look at my sisters cat and wonder what he can understand. My sister's cat is named Boba. He is a good sort of fellow, well behaved, polite... endlessly hungry. Often, I look at him and wonder what he sees. Of course his vision is different ... Read More
More Than a Robot Couch
Fundamentally, engineering is just about choosing whats best. The hard part is just figuring out what is best. Getting caught up in my regrets used to feel like progress. After all, introspection is the first step to improvement. While important, intro... Read More
My Custom 8-Bit CPU
How I learned to let go of small things like ‘value proposition’, ‘opportunity cost’ and ‘reason’ in order to embrace the transistor. In the later half of my internship at AMD in 2019, I was struck by the Muse. I had just seen the Monster 6502, which i... Read More
On The Balance Of Words
Being clear about what you mean is a skill, but being clear while avoiding accountability for the consequences is a profession Everybody knows that lying is wrong. Or at the very least, that lying too much will get you in trouble. Everybody also knows ... Read More
This page has the following tags: Tech
